

v1.1.5 – 2024/01/27 16:12:57 更新
新增如下接口
- IT之家(日榜、周榜、热评榜、月榜)
- 腾讯新闻热点榜
- 微信读书(飙升榜、新书榜、神作榜、小说榜、热搜榜、潜力榜、总榜)
- 起点小说(月票榜、畅销榜、阅读指数榜、推荐榜、收藏榜、签约作者新书榜、公众作家新书榜、月票VIP榜)
- 纵横小说(月票榜、24h畅销榜、新书榜、推荐榜、新书订阅榜、点击榜)
2023/04/13 10:57:37(暂未解决)
有哪位大佬能告知微信的热榜来源,我这边可提供部署api及更新自定义热榜缓存问题 (已解决)
实际使用起来,缓存问题一直解决不了,查了数据库,在后台管理界面设置的几分钟过期,在数据中的过期时间是当前时间的历史时间,根本实现不了缓存失效然后清缓存的操作
实在翻不动iothem主题的代码了,直接在mysql创建一条定时任务事件,每6个小时清除一次热搜的缓存,这样他想不去获取新数据都没办法绕过去了。
CREATE EVENT delete_old_hot_data ON SCHEDULE EVERY 6 HOUR -- 每6小时执行一次 DO DELETE FROM wp_options WHERE option_name like '%hot_data%';我不确定这对性能有什么影响,热榜服务端是部署在与wordpress同服务器中的,响应时间理论是很短的,我对缓存和php都了解不多,就这样吧
vim ./wp-content/themes/onenav/inc/hot-search.php --------------- function io_get_hot_search_data(){ $rule_id = esc_sql($_REQUEST['id']); $type = esc_sql($_REQUEST['type']); #$cache_key = "io_free_hot_data_{$rule_id}_{$type}"; #$_data = get_transient($cache_key); # 注释掉下面两行 #if($_data) # io_error(array("status" => 1, "data" => $_data), false, 10); -------------# 跟上面同一文件中的内容,算是缩减下代码,这个修改只在热榜和博客部署在同服务器才可以这么用 # 下面的内容进行注释 # $_ua = array( # '[dev]general information acquisition module - level 30 min, version:3.2', # "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36", # "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36", # ); # $default_ua = array('userAgent'=>$_ua[wp_rand(0,2)]); # $custom_api = get_option( 'io_hot_search_list' )[$type.'_list']; # $custom_data= $custom_api[$rule_id-1]; # $api_url = $custom_data['url']; # $api_cache = isset($custom_data['cache']) ? (int)$custom_data['cache'] : 60; # $api_data = isset($custom_data['request_data']) ? io_option_data_to_array($custom_data['request_data']) : ''; # $api_method = strtoupper(isset($custom_data['request_type']) ? $custom_data['request_type'] : 'get'); # $api_header = isset($custom_data['headers']) ? io_option_data_to_array($custom_data['headers'], $default_ua) : $default_ua; # $api_cookie = isset($custom_data['cookies']) ? io_option_data_to_array($custom_data['cookies']) : ''; # $http = new Yurun\Util\HttpRequest; # $http->headers($api_header); # if($api_cookie) # $http->cookies($api_cookie); # $response = $http->send($api_url, $api_data, $api_method); ============================================ # 注释下方添加以下内容 $custom_api = get_option( 'io_hot_search_list' )[$type.'_list']; $custom_data= $custom_api[$rule_id-1]; $api_url = $custom_data['url']; $http = new Yurun\Util\HttpRequest; $response = $http->get($api_url);目前主题的自定义热榜JSON数据源有缓存问题,热榜服务端关闭服务,首页还是有数据,并且是好几天前的数据,自定义都不去获取后端数据刷新旧数据,自定义的缓存时间屁用没有。
官方修没指望了,既然给了自定义接口,这是要搞什么?
起因
一年之前我购买了一为的这个One Nav 主题,赠送了一年的热榜API,一年的时间过的嗖嗖的,眼看着API就用不了,小站一枚,一年98的价格比我站点服务器都贵。
既然吝啬自己的钱包,又不舍得让自己这点流量看不到热榜,不妨自己写一写,也分享出来。
本次写代码使用Pycharm写的,配合了一个插件,名字叫做:Codeium ,该插件需要注册才能免费使用
如下图所示,在我还没有写出代码的情况下,插件已经预测了我要写的内容

使用感受就是,你重复代码写的越多,插件就越能理解你要写的什么,他会检索你整个项目下的所有内容,并给出建议,建议采纳与否还是要你自己看代码是否合适。
流程图

更新日志及源代码
| 接口地址 | 接口说明 |
| IP:5000/wuai | 吾爱破解的人气热门 |
| ip:5000/zhihu | 知乎热榜 |
| ip:5000/bili/day | bilibili全站日榜 |
| ip:5000/bili/hot | bilibili热搜榜 |
| ip:5000/acfun | afcun热榜 |
| ip:5000/hupu | 虎扑热榜 |
| ip:5000/smzdm | 什么值得买热榜 |
| ip:5000/weibo | 微博热榜 |
| ip:5000/tieba | 贴吧热议榜 |
| ip:5000/weixin | 这个接口不能用 |
| ip:5000/ssp | 少数派热榜 |
| ip:5000/36k/renqi | 36氪人气榜 |
| ip:5000/36k/zonghe | 36氪综合榜 |
| ip:5000/36k/shoucang | 36氪收藏榜 |
| ip:5000/baidu | 百度热榜 |
| ip:5000/douyin | 抖音热榜 |
| ip:5000/csdn | CSDN热榜 |
| ip:5000/history | 历史上的今天(魔法) |
| ip:5000/douban | 豆瓣新片榜 |
| ip:5000/ghbk | 果核剥壳 |
| ip:5000/it/day | IT之家_日榜 |
| ip:5000/it/week | IT之家_周榜 |
| ip:5000/it/hot | IT之家_热评榜 |
| ip:5000/it/month | IT之家_月榜 |
| ip:5000/tencent | 腾讯新闻热点榜 |
| ip:5000/wxbook/soar | 微信读书_飙升榜 |
| ip:5000/wxbook/new | 微信读书_新书榜 |
| ip:5000/wxbook/god | 微信读书_神作榜 |
| ip:5000/wxbook/novel | 微信读书_小说榜 |
| ip:5000/wxbook/hot | 微信读书_热搜榜 |
| ip:5000/wxbook/potential | 微信读书_潜力榜 |
| ip:5000/wxbook/all | 微信读书_总榜 |
| ip:5000/qidian/yuepiao | 起点中文网_月票榜 |
| ip:5000/qidian/changxiao | 起点中文网_畅销榜 |
| ip:5000/qidian/zhisu | 起点中文网_阅读指数榜 |
| ip:5000/qidian/tuijina | 起点中文网_推荐榜 |
| ip:5000/qidian/shoucang | 起点中文网_收藏榜 |
| ip:5000/qidian/new | 起点中文网_签约作者新书榜 |
| ip:5000/qidian/new_2 | 起点中文网_公众作家新书榜 |
| ip:5000/qidian/yuepiao_vip | 起点中文网_月票_VIP榜 |
| ip:5000/zongheng/yuepiao | 纵横中文网_月票榜 |
| ip:5000/zongheng/24h | 纵横中文网_24h畅销榜 |
| ip:5000/zongheng/new | 纵横中文网_新书榜 |
| ip:5000/zongheng/tuijian | 纵横中文网_推荐榜 |
| ip:5000/zongheng/new_dingyue | 纵横中文网_新书订阅榜 |
| ip:5000/zongheng/dianji | 纵横中文网_点击榜 |
| 接口地址 | 接口说明 |
| ip:5000/get_wuai_data | 吾爱破解的人气热门 |
| ip:5000/get_zhihu_data | 知乎热榜 |
| ip:5000/get_bilibili_data | bilibili全站日榜 |
| ip:5000/get_bilibili_hot | bilibili热搜榜 |
| ip:5000/get_acfun_data | afcun热榜 |
| ip:5000/get_hupu_data | 虎扑热榜 |
| ip:5000/get_smzdm_data | 什么值得买热榜 |
| ip:5000/get_weibo_data | 微博热榜 |
| ip:5000/get_tieba_data | 贴吧热议榜 |
| ip:5000/get_weixin_data | 这个接口不能用 |
| ip:5000/get_ssp_data | 少数派热榜 |
| ip:5000/get_36k_data/renqi | 36氪人气榜 |
| ip:5000/get_36k_data/zonghe | 36氪综合榜 |
| ip:5000/get_36k_data/shoucang | 36氪收藏榜 |
新增如下接口
- IT之家(日榜、周榜、热评榜、月榜)
- 腾讯新闻热点榜
- 微信读书(飙升榜、新书榜、神作榜、小说榜、热搜榜、潜力榜、总榜)
- 起点小说(月票榜、畅销榜、阅读指数榜、推荐榜、收藏榜、签约作者新书榜、公众作家新书榜、月票VIP榜)
- 纵横小说(月票榜、24h畅销榜、新书榜、推荐榜、新书订阅榜、点击榜)
隐藏内容!
评论后才能查看!
- 移除讯代理相关代码,使用免费的代理接口(免费相对不稳定,但是可以用)
- 新增如下接口
- 历史上的今天
- 需要你的机器能访问zh.wikipedia.org这个网站(可能需要魔法),没有找到其他更好的网站了
- 豆瓣新片
- 果核剥壳
- 历史上的今天
隐藏内容!
登录后才能查看!
- 修复52论坛、知乎访问
- 关于52论坛,如果访问量上去了,会出现403权限拒绝的现象,这个解决方法就是加个代理
- 我这里使用的讯代理,如果需要其他代理的支持,可以联系我
- 讯代理这边9元1000个ip,然后把global_timeout_file参数设置为24,这样一天最多使用一个,1000个可以用1000天(3年)
- 讯代理地址:该站点已停止运行!!!!!
- 注册成功后
- 点击顶部菜单栏中的【购买代理】
- 选择优质代理,点击下方的【选择购买】
- 在弹出的购买代理对话框中
- 套餐类型选择【按量】
- 然后点击【确定购买】
- 购买后在网站的顶部菜单栏中点击【API接口】【优质代理API】
- 选择你购买的订单
- 提取数列选择【1】
- 数据格式选择【JSON】
- 点击【生成API链接】
- 将生成的链接复制到代码的双引号中【proxy_address = “”】
- 关于52论坛,如果访问量上去了,会出现403权限拒绝的现象,这个解决方法就是加个代理
- 修复访问网站,代码提示443
隐藏内容!
登录后才能查看!
隐藏内容!
登录后才能查看!
- 修复缓存文件一个小时后不更新的问题
- 新增csdn热榜
隐藏内容!
登录后才能查看!
- 优化代码为500行以内
- 更新百度热榜、抖音热榜
- 优化接口名称(将接口名简短表示)
- 修复若干bug
- 请看最新版本接口(本版本存在bug),不删除是因为要留存版本记录
隐藏内容!
登录后才能查看!
- 600多行PY代码
- 涉及吾爱、知乎、bilibili、acfun、虎扑、什么值得买、微博、贴吧、少数派、36氪
- 本版本相对于高版本只是接口不再更新,代码复用率低点,乱点,bug还是会同高版本同时修复
"""
@author: webra
@time: 2023/3/27 13:31
@description:
@update: 2023/04/03 14:29:35
"""
import glob
import re
import time
import requests
from bs4 import BeautifulSoup
import datetime
import json
from lxml import etree
import random
import os
from flask import Flask
now = datetime.datetime.now()
timestamp = int(time.time())
app = Flask(__name__)
def read_file(file_path):
with open(file_path, 'r') as f:
content = f.read()
return content
def del_file(file_path):
if os.path.exists(file_path):
os.remove(file_path)
def write_file(file_path, content):
with open(file_path, 'w', encoding='utf-8') as f:
f.write(content)
@app.route("/")
def index():
data_dict = {"get_wuai_data": "吾爱热榜",
"get_zhihu_data": "知乎热榜",
"get_bilibili_data": "bilibili全站日榜",
"get_bilibili_hot": "bilibili热搜榜",
"get_acfun_data": "acfun热榜",
"get_hupu_data": "虎扑步行街热榜",
"get_smzdm_data": "什么值得买热榜",
"get_weibo_data": "微博热榜",
"get_tieba_data": "百度贴吧热榜",
"get_weixin_data": "微信热榜",
"get_ssp_data": "少数派热榜",
"get_36k_data": "36Kr热榜"}
json_data = {}
json_data["secure"] = True
json_data["title"] = "热榜接口"
json_data["update_time"] = now.strftime("%Y-%m-%d %H:%M:%S")
json_data["data"] = data_dict
return json.dumps(json_data, ensure_ascii=False)
@app.route("/test")
def test():
return "test"
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Mobile Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.246",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.246",
"Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.246",
"Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; AS; rv:11.0) like Gecko",
"Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; AS; rv:11.0) like Gecko",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; AS; rv:11.0) like Gecko",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; Trident/7.0; AS; rv:11.0) like Gecko",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:54.0) Gecko/20100101 Firefox/54.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"
]
def random_user_agent():
return random.choice(user_agents)
def get_html(url, headers, cl=None):
response = requests.get(url, headers=headers, stream=True)
if cl is not None:
return response
html = BeautifulSoup(response.text, 'html.parser')
return html
def get_data(filename, filename_re):
file_names = glob.glob('./data/' + filename)
file_names_len = len(file_names)
if file_names_len == 1:
# 文件名
file_name = file_names[0]
old_timestamp = int(re.findall(filename_re, file_name)[0])
old_timestamp_datetime_obj = datetime.datetime.fromtimestamp(int(old_timestamp))
time_diff = datetime.datetime.now() - old_timestamp_datetime_obj
if time_diff > datetime.timedelta(hours=1):
del_file(file_name)
return None
else:
return read_file(file_name)
else:
if file_names_len > 1:
[del_file(file_name) for file_name in file_names]
return None
# 吾爱热榜
@app.route("/get_wuai_data")
def get_wuai_data():
filename = "wuai_data_*.data"
filename_re = "wuai_data_(.*?).data"
file_content = get_data(filename, filename_re)
if file_content is None:
json_data = {}
data_list = []
json_data["secure"] = True
json_data["title"] = "吾爱热榜"
json_data["update_time"] = now.strftime("%Y-%m-%d %H:%M:%S")
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"User-Agent": random_user_agent()
}
html = get_html("https://www.52pojie.cn/forum.php?mod=guide&view=hot", headers)
articles = html.find_all('a', {'class': {"xst"}})
articles_hot = html.find_all('span', {'class': {"xi1"}})
num = 1
for article, hot in zip(articles, articles_hot):
data_dict = {}
data_dict["index"] = num
data_dict["title"] = article.string.strip()
data_dict["url"] = "https://www.52pojie.cn/" + article.get('href')
data_dict["hot"] = hot.string.strip()[:-3]
num += 1
data_list.append(data_dict)
json_data["data"] = data_list
data = json.dumps(json_data, ensure_ascii=False)
filename = "wuai_data_" + str(timestamp) + ".data"
write_file("./data/" + filename, data)
return data
else:
return file_content
# 知乎热榜
@app.route("/get_zhihu_data")
def get_zhihu_data():
filename = "zhihu_data_*.data"
filename_re = "zhihu_data_(.*?).data"
file_content = get_data(filename, filename_re)
if file_content is None:
json_data = {}
data_list = []
json_data["secure"] = True
json_data["title"] = "知乎热榜"
json_data["update_time"] = now.strftime("%Y-%m-%d %H:%M:%S")
headers = {
'cookie': '_zap=3195f691-793a-404b-a1c2-a152ead6b0ef; d_c0=AYBTpKH7IxaPTlkD0uawrZWC1OzdedJsmVg=|1673151895; ISSW=1; YD00517437729195:WM_TID=dCD5z+kvXkZBERAERReVJ4HqjJV+UbEX; _xsrf=ZRKz2ahWNVIiiMuVsgwncHmiJEnJfxNP; __snaker__id=0oLAfHUBBwwPa2yi; YD00517437729195:WM_NI=aUaJNpP+BSZZKrXd9A4FtimocRtXflmIudVaB2GQ3pbhE4PJ/ZZQbOxBl7emji362eQ1fwxZYVDH4VyUpXdoZgqArTuIoIC+WCUJeEIZyTNSJhClos1zt2x+AhoVOlM+SFQ=; YD00517437729195:WM_NIKE=9ca17ae2e6ffcda170e2e6eea2b36bf5f1f783e9468a8a8eb6c15e869b8eb1c8458cafffd8e66da3b781ccd82af0fea7c3b92aa38bafabcd7c94f58eb4d95289ae9885bc4bf89abc8af065a18ebcb9e568af97bb85d56b82ee89b2b27ca2b88bd5d342ed8696b2e145bc9ea4d8e867aab7fdd7b16f93efaa98fb529b8a8ca9b75ebb8bc0b9e7659ab9bfa2f160b797a1aac221959d9babe84f8b86b7b5cd598ab88d8dee79f3a6bcd3fb2183b8a1b7ce688ff59da7d437e2a3; q_c1=0b5f766a729d4411b01730ae52526275|1677133529000|1677133529000; tst=h; z_c0=2|1:0|10:1679897427|4:z_c0|80:MS4xMjVueENnQUFBQUFtQUFBQVlBSlZUVk9CRG1VaWJoVGFZQ0JYaTczbzNLcy1qRXlucUc4SGlRPT0=|2071b379b81c9c1ee8a391002cd616468bc31ac1c1883f75bfaf93f099c5bce3; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1679672991,1679721877,1679839421,1679897389; SESSIONID=XB0nPsBsUVHWlgxviypJUHFVjvA26oSiK1qkBbd9VO7; JOID=W1gQBEJCI1qbP0u7NExKANeQvpEuE2Ro-28x_EUXfBfOXSzKRx0Xd_E2R7w4R0VDXFi445KUxEew11n4txI14hY=; osd=U1ASB09KK1iYMkOzNk9HCN-SvZwmG2Zr9mc5_kYadB_MXiHCTx8Uevk-Rb81T01BX1Ww65CXyU-41Vr1vxo34Rs=; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1679901672; KLBRSID=81978cf28cf03c58e07f705c156aa833|1679902388|1679897426',
'referer': 'https://www.zhihu.com/',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': random_user_agent()
}
html = get_html("https://www.zhihu.com/hot", headers, 1)
etree_html = etree.HTML(html.content.decode('utf-8'))
articles_title = etree_html.xpath('//*[@id="TopstoryContent"]/div/div/div[1]/section/div[2]/a/@title')
articles_url = etree_html.xpath('//*[@id="TopstoryContent"]/div/div/div[1]/section/div[2]/a/@href')
articles_hot = etree_html.xpath('//*[@id="TopstoryContent"]/div/div/div[1]/section/div[2]/div/text()')
num = 1
for title, url, hot in zip(articles_title, articles_url, articles_hot):
data_dict = {}
data_dict["index"] = num
num += 1
data_dict["title"] = title
data_dict["url"] = url
data_dict["hot"] = hot[:-2]
data_list.append(data_dict)
json_data["data"] = data_list
data = json.dumps(json_data, ensure_ascii=False)
filename = "zhihu_data_" + str(timestamp) + ".data"
write_file("./data/" + filename, data)
return data
else:
return file_content
# bilibili全站日榜,无got节点
@app.route("/get_bilibili_data")
def get_bilibili_data():
filename = "bilibili_data_*.data"
filename_re = "bilibili_data_(.*?).data"
file_content = get_data(filename, filename_re)
if file_content is None:
json_data = {}
data_list = []
json_data["secure"] = True
json_data["title"] = "哔哩哔哩全站热榜"
json_data["update_time"] = now.strftime("%Y-%m-%d %H:%M:%S")
headers = {
"User-Agent": random_user_agent()
}
html = get_html("https://api.bilibili.com/x/web-interface/ranking/v2?rid=0&type=all", headers, 1)
html_dict = json.loads(html.text)
num = 1
for key in html_dict["data"]["list"]:
data_dict = {}
data_dict["index"] = num
num += 1
data_dict["title"] = key["title"]
data_dict["url"] = key["short_link"]
data_dict["hot"] = ""
data_list.append(data_dict)
json_data["data"] = data_list
data = json.dumps(json_data, ensure_ascii=False)
filename = "bilibili_data_" + str(timestamp) + ".data"
print(filename)
write_file("./data/" + filename, data)
return data
else:
return file_content
# bilibili热搜榜
@app.route("/get_bilibili_hot")
def get_bilibili_hot():
filename = "bilibili_hot_*.data"
filename_re = "bilibili_hot_(.*?).data"
file_content = get_data(filename, filename_re)
if file_content is None:
json_data = {}
data_list = []
json_data["secure"] = True
json_data["title"] = "bilibili热搜榜"
json_data["update_time"] = now.strftime("%Y-%m-%d %H:%M:%S")
res = requests.get("https://app.bilibili.com/x/v2/search/trending/ranking")
html_dict = json.loads(res.text)
for key in html_dict["data"]["list"]:
data_dict = {}
data_dict["index"] = key["position"]
data_dict["title"] = key["show_name"]
url = "https://search.bilibili.com/all?keyword=" + key[
"keyword"] + "&from_source=webtop_search&spm_id_from=333.934"
data_dict["url"] = url
data_dict["hot"] = ""
data_list.append(data_dict)
json_data["data"] = data_list
data = json.dumps(json_data, ensure_ascii=False)
filename = "bilibili_hot_" + str(timestamp) + ".data"
write_file("./data/" + filename, data)
return data
else:
return file_content
# acfun热榜
@app.route("/get_acfun_data")
def get_acfun_data():
filename = "acfun_data_*.data"
filename_re = "acfun_data_(.*?).data"
file_content = get_data(filename, filename_re)
if file_content is None:
json_data = {}
data_list = []
json_data["secure"] = True
json_data["title"] = "acfun热榜"
json_data["update_time"] = now.strftime("%Y-%m-%d %H:%M:%S")
headers = {
'referer': 'https://www.acfun.cn/',
'user-agent': random_user_agent()
}
res = get_html("https://www.acfun.cn/rest/pc-direct/rank/channel?channelId=&subChannelId=&rankLimit=30&rankPeriod=DAY", headers, 1)
html_dict = json.loads(res.text)
num = 1
for key in html_dict["rankList"]:
data_dict = {}
data_dict["index"] = num
num += 1
data_dict["title"] = key["title"]
data_dict["url"] = key["shareUrl"]
data_dict["hot"] = key["viewCountShow"]
data_list.append(data_dict)
json_data["data"] = data_list
data = json.dumps(json_data, ensure_ascii=False)
filename = "acfun_data_" + str(timestamp) + ".data"
write_file("./data/" + filename, data)
return data
else:
return file_content
# 虎扑步行街热榜
@app.route("/get_hupu_data")
def get_hupu_data():
filename = "hupu_data_*.data"
filename_re = "hupu_data_(.*?).data"
file_content = get_data(filename, filename_re)
if file_content is None:
json_data = {}
data_list = []
json_data["secure"] = True
json_data["title"] = "虎扑步行街热榜"
json_data["update_time"] = now.strftime("%Y-%m-%d %H:%M:%S")
headers = {
'referer': 'https://hupu.com/',
'user-agent': random_user_agent()
}
res = requests.get("https://bbs.hupu.com/all-gambia", headers=headers)
etree_html = etree.HTML(res.text)
articles_title = etree_html.xpath('//*[@id="container"]/div/div[2]/div/div[2]/div/div[2]/div/div/div/div[1]/a/span/text()')
articles_url = etree_html.xpath('//*[@id="container"]/div/div[2]/div/div[2]/div/div[2]/div/div/div/div[1]/a/@href')
articles_top = etree_html.xpath('//*[@id="container"]/div/div[2]/div/div[2]/div/div[2]/div/div/div/div[1]/span[1]/text()')
num = 1
for title, url, top in zip(articles_title, articles_url, articles_top):
data_dict = {}
data_dict["index"] = num
num += 1
data_dict["title"] = title
data_dict["url"] = "https://bbs.hupu.com/" + url
data_dict["top"] = top
data_list.append(data_dict)
json_data["data"] = data_list
data = json.dumps(json_data, ensure_ascii=False)
filename = "hupu_data_" + str(timestamp) + ".data"
write_file("./data/" + filename, data)
return data
else:
return file_content
# 什么值得买热榜(日榜)
@app.route("/get_smzdm_data")
def get_smzdm_data():
filename = "smzdm_data_*.data"
filename_re = "smzdm_data_(.*?).data"
file_content = get_data(filename, filename_re)
if file_content is None:
json_data = {}
data_list = []
json_data["secure"] = True
json_data["title"] = "什么值得买热榜"
json_data["update_time"] = now.strftime("%Y-%m-%d %H:%M:%S")
headers = {
'referer': 'https://smzdm.com/',
'user-agent': random_user_agent()
}
res = requests.get("https://post.smzdm.com/hot_1/", headers=headers)
etree_html = etree.HTML(res.text)
articles_title = etree_html.xpath('//*[@id="feed-main-list"]/li/div/div[2]/h5/a/text()')
articles_url = etree_html.xpath('//*[@id="feed-main-list"]/li/div/div[2]/h5/a/@href')
articles_top = etree_html.xpath('//*[@id="feed-main-list"]/li/div/div[2]/div[2]/div[2]/a[1]/span[2]/text()')
num = 1
for title, url, top in zip(articles_title, articles_url, articles_top):
data_dict = {}
data_dict["index"] = num
num += 1
data_dict["title"] = title
data_dict["url"] = url
data_dict["top"] = top
data_list.append(data_dict)
json_data["data"] = data_list
data = json.dumps(json_data, ensure_ascii=False)
filename = "smzdm_data_" + str(timestamp) + ".data"
print(data)
write_file("./data/" + filename, data)
return data
else:
return file_content
# 微博热榜
@app.route("/get_weibo_data")
def get_weibo_data():
filename = "weibo_data_*.data"
filename_re = "weibo_data_(.*?).data"
file_content = get_data(filename, filename_re)
if file_content is None:
json_data = {}
data_list = []
json_data["secure"] = True
json_data["title"] = "微博热榜"
json_data["update_time"] = now.strftime("%Y-%m-%d %H:%M:%S")
headers = {
'referer': 'https://smzdm.com/',
'user-agent': random_user_agent()
}
res = requests.get("https://weibo.com/ajax/statuses/hot_band", headers=headers)
html_dict = json.loads(res.text)
for key in html_dict["data"]["band_list"]:
try:
data_dict = {}
data_dict["index"] = key["realpos"]
data_dict["title"] = key["word"]
data_dict["url"] = "https://s.weibo.com/weibo?q=%23" + key["word"] + "%23"
data_dict["hot"] = key["num"]
except KeyError:
continue
data_list.append(data_dict)
json_data["data"] = data_list
data = json.dumps(json_data, ensure_ascii=False)
filename = "weibo_data_" + str(timestamp) + ".data"
write_file("./data/" + filename, data)
return data
else:
return file_content
# 百度贴吧热议榜
@app.route("/get_tieba_data")
def get_tieba_data():
filename = "tieba_data_*.data"
filename_re = "tieba_data_(.*?).data"
file_content = get_data(filename, filename_re)
if file_content is None:
json_data = {}
data_list = []
json_data["secure"] = True
json_data["title"] = "百度贴吧热议榜"
json_data["update_time"] = now.strftime("%Y-%m-%d %H:%M:%S")
import requests
headers = {
'referer': 'https://tieba.baidu.com/',
'user-agent': random_user_agent()
}
res = requests.get("https://tieba.baidu.com/hottopic/browse/topicList?res_type=1", headers=headers)
etree_html = etree.HTML(res.text)
articles_title = etree_html.xpath('/html/body/div[2]/div/div[2]/div/div[2]/div[1]/ul/li/div/div/a/text()')
articles_url = etree_html.xpath('/html/body/div[2]/div/div[2]/div/div[2]/div[1]/ul/li/div/div/a/@href')
articles_top = etree_html.xpath('/html/body/div[2]/div/div[2]/div/div[2]/div[1]/ul/li/div/div/span[2]/text()')
num = 1
for title, url, top in zip(articles_title, articles_url, articles_top):
data_dict = {}
data_dict["index"] = num
num += 1
data_dict["title"] = title
data_dict["url"] = url
data_dict["top"] = top.replace("实时讨论", "")
data_list.append(data_dict)
json_data["data"] = data_list
data = json.dumps(json_data, ensure_ascii=False)
filename = "tieba_data_" + str(timestamp) + ".data"
write_file("./data/" + filename, data)
return data
else:
return file_content
# 微信热榜
# @app.route("/get_weixin_data")
# def get_weixin_data():
# json_data = {}
# data_list = []
# json_data["secure"] = True
# json_data["title"] = "微信热榜"
# json_data["update_time"] = now.strftime("%Y-%m-%d %H:%M:%S")
# import requests
# headers = {
# 'referer': 'https://tophub.today/',
# 'user-agent': random_user_agent()
# }
# res = requests.get("https://tophub.today/n/WnBe01o371", headers=headers)
# etree_html = etree.HTML(res.text)
# articles_title = etree_html.xpath('//*[@id="page"]/div[2]/div[2]/div[1]/div[2]/div/div[1]/table/tbody/tr/td[2]/a/text()')
# articles_url = etree_html.xpath('//*[@id="page"]/div[2]/div[2]/div[1]/div[2]/div/div[1]/table/tbody/tr/td[2]/a/@href')
# articles_top = etree_html.xpath('//*[@id="page"]/div[2]/div[2]/div[1]/div[2]/div/div[1]/table/tbody/tr/td[3]/text()')
# num = 1
# for title, url, top in zip(articles_title, articles_url, articles_top):
# data_dict = {}
# data_dict["index"] = num
# num += 1
# data_dict["title"] = title
# data_dict["url"] = "https://tophub.today" + url
# data_dict["top"] = top
# data_list.append(data_dict)
# json_data["data"] = data_list
# return json.dumps(json_data, ensure_ascii=False)
# 少数派热榜
@app.route("/get_ssp_data")
def get_ssp_data():
filename = "ssp_data_*.data"
filename_re = "ssp_data_(.*?).data"
file_content = get_data(filename, filename_re)
if file_content is None:
json_data = {}
data_list = []
json_data["secure"] = True
json_data["title"] = "少数派热榜"
json_data["update_time"] = now.strftime("%Y-%m-%d %H:%M:%S")
headers = {
'referer': 'https://sspai.com/',
'user-agent': random_user_agent()
}
res = requests.get(
"https://sspai.com/api/v1/article/tag/page/get?limit=100000&tag=%E7%83%AD%E9%97%A8%E6%96%87%E7%AB%A0",
headers=headers)
html_dict = json.loads(res.text)
num = 1
for key in html_dict["data"]:
try:
data_dict = {}
data_dict["index"] = num
num += 1
data_dict["title"] = key["title"]
data_dict["url"] = "https://sspai.com/post/" + str(key["id"])
data_dict["top"] = key["like_count"]
except KeyError:
continue
data_list.append(data_dict)
json_data["data"] = data_list
data = json.dumps(json_data, ensure_ascii=False)
filename = "ssp_data_" + str(timestamp) + ".data"
write_file("./data/" + filename, data)
return data
else:
return file_content
# 36Kr热榜
@app.route("/get_36k_data")
def html_get_36k_data():
json_data = {}
json_data["secure"] = True
json_data["title"] = "36Kr热榜"
json_data["update_time"] = now.strftime("%Y-%m-%d %H:%M:%S")
data = [
{"type": "renqi"},
{"type": "shoucang"},
{"type": "zonghe"}
]
json_data["data"] = data
return json.dumps(json_data, ensure_ascii=False)
@app.route("/get_36k_data/<type>")
def get_36k_data_type(type):
if type == "renqi":
return get_36k_data("renqi")
elif type == "shoucang":
return get_36k_data("shoucang")
elif type == "zonghe":
return get_36k_data("zonghe")
else:
json_data = {}
json_data["secure"] = False
json_data["title"] = "Error"
return json.dumps(json_data, ensure_ascii=False)
# type = renqi| zonghe| shoucang
def get_36k_data(type):
json_data = {}
data_list = []
json_data["update_time"] = now.strftime("%Y-%m-%d %H:%M:%S")
filename = "36kr_" + type + "_data_*.data"
filename_re = "36kr_" + type + "_data_(.*?).data"
if type == "renqi":
title = "36Kr人气榜"
elif type == "zonghe":
title = "36Kr综合榜"
elif type == "shoucang":
title = "36Kr收藏榜"
else:
json_data["secure"] = False
json_data["title"] = "Error"
return json.dumps(json_data, ensure_ascii=False)
file_content = get_data(filename, filename_re)
if file_content is None:
json_data["secure"] = True
json_data["title"] = title
headers = {
'referer': 'https://www.36kr.com/',
'user-agent': random_user_agent()
}
url = "https://www.36kr.com/hot-list/" + type + "/" + now.strftime("%Y-%m-%d") + "/1"
res = requests.get(url, headers=headers)
etree_html = etree.HTML(res.text)
articles_title = etree_html.xpath('//*[@id="app"]/div/div[2]/div[3]/div/div/div[2]/div[1]/div/div/div/div/div[2]/div[2]/a/text()')
articles_url = etree_html.xpath('//*[@id="app"]/div/div[2]/div[3]/div/div/div[2]/div[1]/div/div/div/div/div[2]/div[2]/a/@href')
articles_top = etree_html.xpath('//*[@id="app"]/div/div[2]/div[3]/div/div/div[2]/div[1]/div/div/div/div/div[2]/div[2]/div/span/span/text()')
num = 1
for title, url, top in zip(articles_title, articles_url, articles_top):
data_dict = {}
data_dict["index"] = num
num += 1
data_dict["title"] = title
data_dict["url"] = "https://www.36kr.com" + url
data_dict["top"] = top.replace("热度", "")
data_list.append(data_dict)
json_data["data"] = data_list
data = json.dumps(json_data, ensure_ascii=False)
filename = "36kr_" + type + "_data_" + str(timestamp) + ".data"
write_file("./data/" + filename, data)
return data
else:
return file_content
if __name__ == "__main__":
app.run()代码可以优化,我是知道的,重复内容挺多的,但是,但是,但是它能运行,且可以获取到我想要的内容,我暂时不想优化,不想优化,不想优化,代码很简单,相当于一个又一个的例子,你如果有点编程基础的话,应该不难看懂,我就不多解释了哈。
2023/04/01 1:32:12最终还是优化了,发现新增其他热榜有点不友好。
部署方法
wiuid/webra_hot_api: 自建热门网站的热榜 (github.com)
- 打开该地址
- 下载webra_top.zip包
- 将该压缩包放置在linux_x86_64的系统上
# 将下载下来的webra_top.zip 进行解压缩
unzip webra_top.zip
cd webra_top
# 赋予执行权限,init是用shell语句写的
chmod +x init
./init
Usage: ./init.sh {start|stop|restart|status}
# 启动
./init start
# 关闭
./init stop
# 重启
./init restart
# 查看状态
./init status
# 查看端口监听是否存在
ss -tanpl
State Recv-Q Send-Q Local Address:Port Peer Address:Port Process
LISTEN 0 128 127.0.0.1:5000 0.0.0.0:* users:(("top",pid=106379,fd=3))
请确保你的环境有py3,这里不做过多介绍
下面一切内容在你是linux服务器上执行
# 找个位置拷贝代码
# 比如/root 这个路径下创建一个top文件夹
cd top
vim top.py
# 输入i进入编辑模式
# 将上面的代码一股脑粘贴进去
:wq # 保存并退出
# 在top目录下再创建一个data目录,用于数据缓存,同一时间的请求,只爬取一次各个平台的数据
mkdir data
# 在/root/top/路径下,去执行这个
python3 top.py
No Module Named XXX
# 这个时候应该会报没有xxx模块的错误
# 你就执行下面的命令
pip3 install XXX
# 重复几次后,涉及的全部模块应该就装的差不多了
# 能够正常执行后就可以执行最后一条命令了,用于后台运行
nohup python3 top.py &
# 默认5000端口,暂不支持修改运行后,就可以去一为的后台设置自定义热榜了,如下图,其他的模仿着写吧
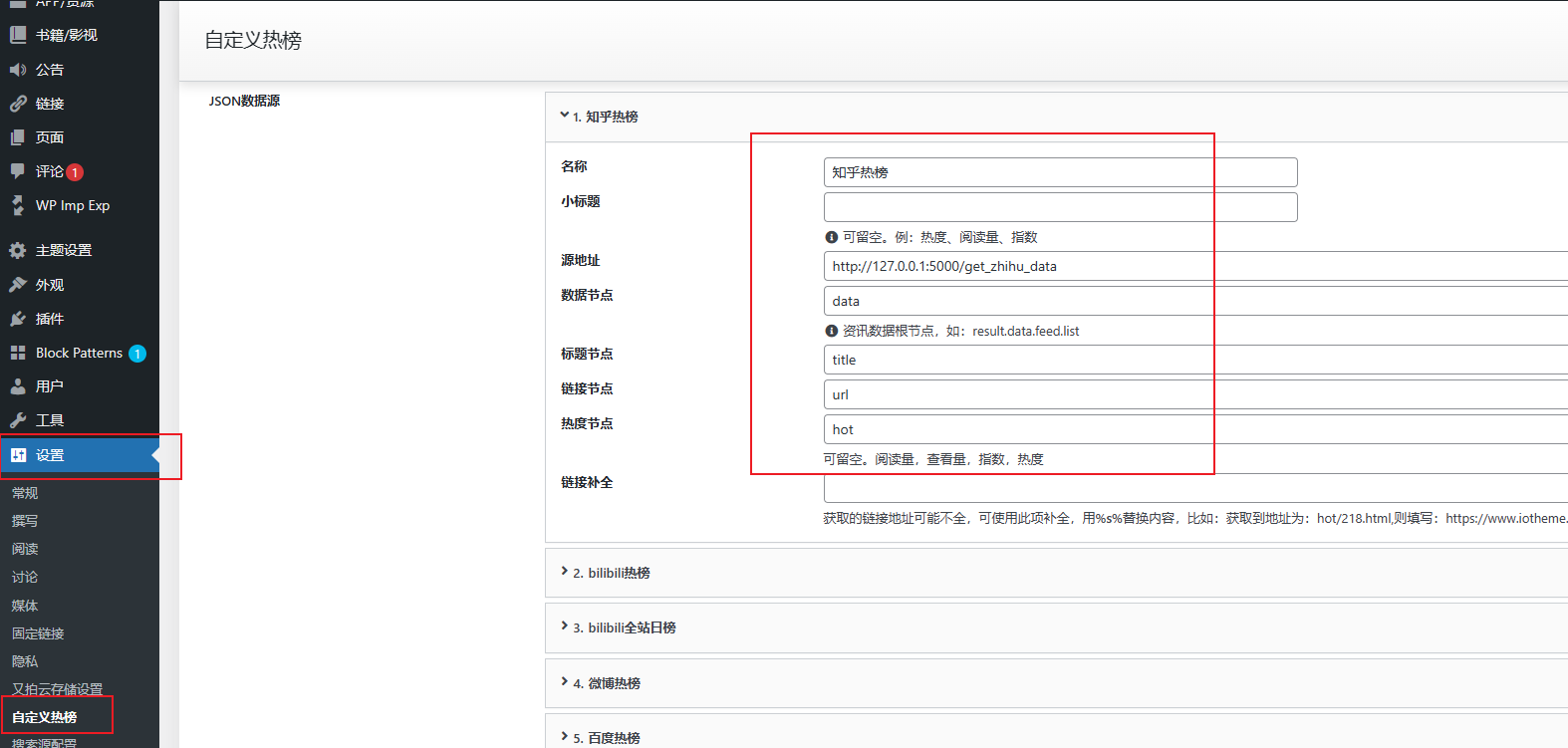
2023/04/14 10:32:12 不再建议使用该方法去部署,该方法部署后,会导致脚本频繁抓取站点信息,导致网站ip被该站点封禁,抓取不到数据
在你站点是使用宝塔的前提下
登录到宝塔后台界面,点击左侧软件商店–>应用搜索并安装以下两个软件,版本选择最新即可
- Python项目管理器
- 进程守护管理器
在软件商店的已安装界面点
击Python项目管理器的设置
- 点击版本管理,选择安装默认显示的python版本即可,点击安装版本,等待安装完成
- 在后台找个目录用于存放top代码
- 比如/root/top目录,在该目录下创建一个data目录
- 将热榜api的代码粘贴进top目录下的top.py文件
- 将以下内容粘贴进top目录下的requirements.txt文件中
- 宝塔软件商店的已安装界面,点击Python项目管理器的项目管理
- 点击添加项目,按照下图进行选择
- 点击确定后就可以对接口进行访问了,访问形式不会因部署方法的改变而改变
beautifulsoup4==4.12.0
bs4==0.0.1
certifi==2022.12.7
charset-normalizer==2.0.12
click==8.0.4
dataclasses==0.8
Flask==2.0.3
idna==3.4
importlib-metadata==4.8.3
itsdangerous==2.0.1
Jinja2==3.0.3
lxml==4.9.2
MarkupSafe==2.0.1
numpy==1.19.5
pandas==1.1.5
python-dateutil==2.8.2
pytz==2023.3
requests==2.27.1
six==1.16.0
soupsieve==2.3.2.post1
typing-extensions==4.1.1
urllib3==1.26.15
Werkzeug==2.0.3
zipp==3.6.0
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



添加小工具
没有一为导航怎么测试调用啊
一为导航的后台设置中有主题自带的自定义热源,可以自己配置接口进行热榜或者其他数据展示。自定义的脚本搭建方法,可以见本文章,详细的后台操作可以加qq群或者微信私聊?
加你了 同意下
图片寄了啊 图片(i.imgur.com/qg3rmss.png) 图片(i.imgur.com/fjiqnxg.png)
这也不知道下一步怎么做啊
目前修复了,有看到吗
感谢站长,今天才看到(12.10),进入讯代理页面。发现正好提示停止运营了。。
没有啊,我用了好久了 这个代{1}理,怎么会停止运营呢?或者加入水友群(侧边栏最下方)、网页最底端有我的微信二维码,可以唠唠嗑
好的,你进官网看一下,那个官网上面写的
淦= =我刚看见 我的眼啊 瞎了 我去找找其他代理,不然52论坛搞不了
大神可以集合到rsshub上面,而且它已经自带来知乎、微博等榜单
一直对rss不太了解,所以也是第一次听rsshub这个东西
我大概看了下,虽然处理方法简单了,但是不能直接用于热榜榜单,还是需要二次加工才可以用,我这个基本框架已经写出来了,再增加新的榜单也容易
哈哈哈,感谢大神回复,我也是个小白,那就用大神的
学习一下,谢谢分享
试试看看被
为什么都是 7
好像是后台没有获取到,或者是你配置的有问题,具体可以加群或者私聊我
学习学习
这个不错
谢谢大哥